
Introduction
In this article I’ll be exploring, one of the most confusing features of JavaScript, the prototype object.
Understanding prototype is necessary to achieve object “inheritance” in JavaScript, which is similar to what you’ve seen in other programming languages.
But first, I’ll be explaining what prototype is, what it can do and how it works, before moving to inheritance.
I’ll start with a simple example.
function A() {
this.message = "hi";
};
A.prototype = {
message: "bye"
};
var obj1 = new A();
alert(obj1.message); //"hi"
You can test the code by clicking this link.
Run the example and you would get the output as “hi” (as expected).
However if you were to delete that property and then try doing an obj.message, you’d get the message “bye”.
delete obj1.message;
alert(obj1.message); //"bye"
How is JavaScript able to do that, even after manually deleting the property?
The answer is, that when the JavaScript engine cannot find ‘message’ within obj1, it starts looking for it within it’s constructor’s prototype object. And in this case, it finds it there and can successfully display it.
In many situations (eg: for debugging), it would be useful to check and verify whether a property is being accessed from the prototype or not. For this purpose, JavaScript defines a method named ‘hasOwnProperty’ to check whether the property is directly owned by the object or not.
At this point, if you do a obj1.hasOwnProperty(‘message’), it would return false, meaning that obj1.message is not direct property of obj1, rather it belongs to it’s constructor’s prototype.
In other words, if you are certain that a property is defined (obj1.message !== undefined), and ‘hasOwnProperty’ on that property returns false, then it can only mean, that the property is being taken from the prototype.
You could verify the above by modifying the first snippet to the following (Code):
alert(obj1.hasOwnProperty('message') ? 'true' : 'false'); //true
delete obj1.message;
alert(obj1.message); //"bye"
alert(obj1.hasOwnProperty('message') ? 'true' : 'false'); //false
“Ok cool! What have we achieved with prototypes?”
A short reply would be: “Cleaner constructor and memory reduction”.
To understand what that means, lets first look at a simpler example:
function E() {};
E.prototype = {
aProperty: "something",
myMethod: function () {
//back-flip
//front-flip
}
};
var obj1 = new E();
var obj2 = new E();
alert(obj1.myMethod);
alert(obj2.myMethod);
Now all instance objects created from constructor E has access to ‘myMethod’. Prototype does this magic for you.
Note that functions are created on execution (dynamically) in javascript and creating more functions increases memory usage. Here the function is defined/created exactly once and is shared among multiple instances of E. This reduces memory consumption.
You don’t have to do a ‘this.myMethod = function() {…}’ on each new instance inside the constructor (which is memory consuming, since a new function is created every time the line is executed).
And my second point, is that we can put non-function properties in the prototype too, so that we don’t need to do a this.aProperty = “something” on each new instance we create.
Even though this doesn’t help us save memory (since JavaScript shares string literals internally) it does help us to keep the constructor’s body clean and avoids repeating and executing the same code on all created instances.
Hence it is a good idea to put all properties that are intended to be shared among multiple instances of a constructor, into the constructor’s prototype.
Internal Stuffs
function C() {};
C.prototype = {
message: "bye"
};
var obj2 = new C();
alert(obj2.message);
From the above, we have understood that C has no properties of its own, yet message can be accessed from the prototype.
At some point you’d probably ponder as to how does JavaScript engines manage to achieve this internally? How does it find its prototype? And how are the internal lookups done?
The answer to the above questions is, that each object you create, has an internal hidden link to its constructor’s prototype. In other words, its like a memory that holds a reference to the prototype.
(Not a big surprise there, but the way JavaScript use these internal links can be interesting. More on that later).
The following is how things would look in memory (I’d call it the “Link diagram”):
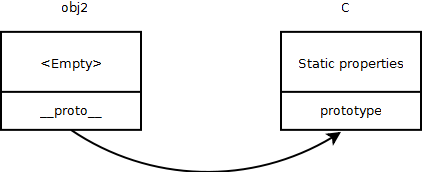
In the image I’ve added an imaginary link to the prototype object named proto. This contains a reference to C’s prototype object.
So when we do a ‘obj2.prop’ and if the JS engine doesn’t find ‘prop’ as a direct property of the the object, then JavaScript uses this hidden link to find it’s constructor’s prototype, and then find the property within it.
[Note: Firefox actually has used to have a hidden proto attribute which you could access. You could check it out with Firebug.]
[Note 2: Ignore “Static properties” and “Static methods” label in the images in this article.]
Inheritance with prototype - the wrong way
function B() {} //Base
B.prototype = {
message: "bye"
}
function D () {} //Derived
D.prototype = B.prototype;
var obj3 = new D();
alert(obj3.message); //bye
Link diagram:
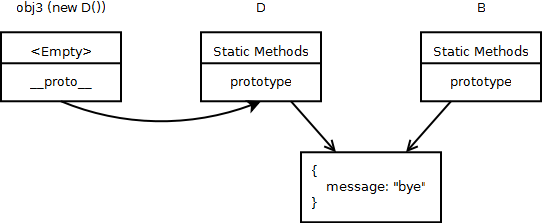
Here D’s prototype is referenced to B’s prototype. Hence when obj3.message is called, JavaScript first looks at whether obj3 has got the property or not.
If it cannot find it in obj3, then it moves on to check it’s constructor’s prototype (that’s D.prototype), and in this case D’s prototype is pointing at B.prototype, hence it finds ‘message’ within that object.
Note that B and D are sharing a single object as it’s prototype. Which means, modifying the shared object will affect both B and D. Say that, you do a D.prototype.prop = “hi”, then that change you have done to the object will also affect B. In most cases, this isn’t what you intended to do. Hence this brings us to the major problem of this type of “inheritance”.
Inheritance with prototype - the right way
So to solve the above mentioned problem, we’d have to think of a way where B and D gets their own copy of the object and its properties. In that way, changes made to one’s prototype will not affect the other’s prototype. And while solving that, we’d also have to think of a way to keep the link to each other’s prototype so that if a property isn’t found in the derived “class”, then we need JavaScript to take it from it’s parent “class” (and this should be recursive).
Complex right? Alright! Now forget everything what I said in the last paragraph :P
function P() { //Proxy
}
P.prototype = B.prototype;
var newInstance = new P();
D.prototype = newInstance;
var obj4 = new D();
alert(obj4.message); //bye
(The above code can make your head spin. But I’ll try to explain it :D)
In the above code, line 1-4, makes a new constructor with it’s prototype pointing to B’s prototype, and then creates a new instance of P. The following is a how things would look in memory:
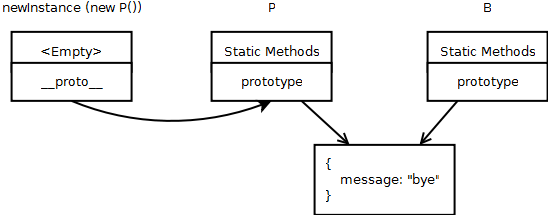
After line 5, the link diagram would be like the following:
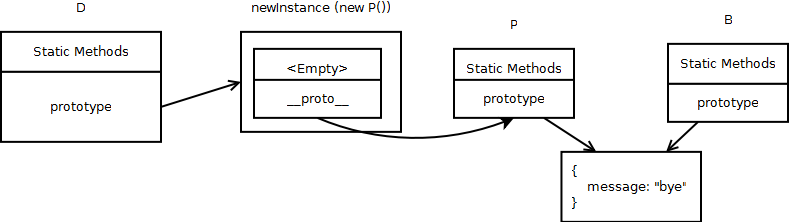
And finally with obj4:
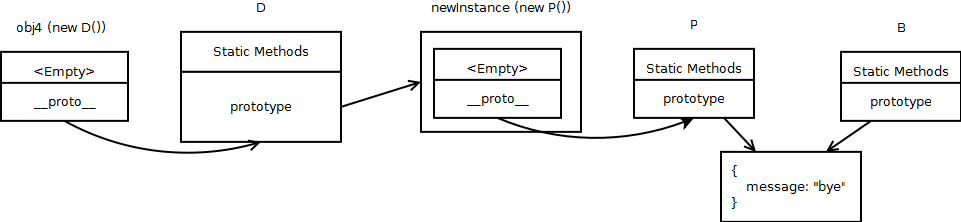
So now when you try to access obj4.message, JavaScript engine goes through the following steps to locate ‘message’:
- First JavaScript checks whether obj4 has got it’s own property named ‘message’ or not.
- If not, use proto to go to obj4’s constructor’s prototype (that is D’s prototype). Since D.prototype = newInstance, JavaScript reaches newInstance and checks whether it has a property named ‘message’. newInstance does not have any property of its own, and only has proto, which is a link to it’s constructor’s prototype.
- Since it couldn’t find newInstance.message, JavaScript now uses newInstance’s proto link to find P’s prototype. Since P.prototype and B.prototype are referencing (sharing) the same object, JavaScript reaches B’s prototype and finally finds ‘message’ there.
Note that this procedure of traversing from one object to another using proto to find the referenced property, is recursive (which is the “interesting” thing I promised to mention at section 2 :D).
So what have we gained with this method of inheritance?
We’ll, now we can change D’s prototype independent of B’s prototype.
If I do a D.prototype.message=”hi”, we would get a link diagram as follows:
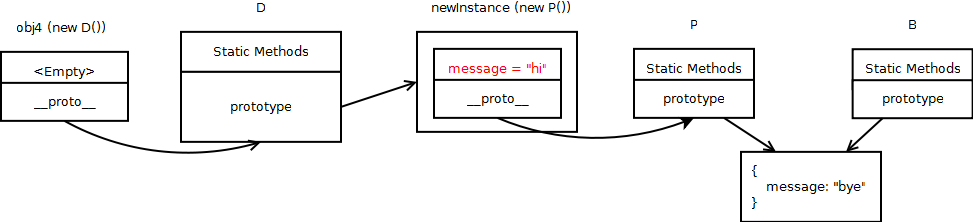
Doing a obj4.message will now return value of D.prototype.message. So effectively, D.prototype.message now “hides” B.prototype.message. Deleting D.prototype.message would “unhide” B.prototype.message.
Hence we achieved the inheritance we desired.
So the final code to achieve inheritance would be as follows:
/**
* @param {Function} B Base (or parent) constructor.
* @param {Function} D Derived (or child) constructor.
* @returns {Function} D
*/
function extend(B, D) {
function P() {} //Proxy
P.prototype = (B.prototype || {}); //If B.prototype isn't defined use empty object
var newInstance = new P();
D.prototype = newInstance;
//Additionally, we could also have a reference to the base and derived constructors.
D.prototype.constructor = D;
D.superclass = B;
return D;
}
That’s all folks.